近日,程金平研究员团队在环境领域著名期刊《Water Research》在线发表了题为“An Attention Fusion of Fourier-Analysis-based Transformer and CNN-BiLSTM for Coastal Inorganic Nitrogen Concentration Forecasts”的研究成果。2024级博士生徐喆枫为论文第一作者,程金平研究员为论文通讯作者。论文第一作者及第一通讯单位均为香港AV 。
01研究背景
准确预测沿海无机氮浓度对减轻有害藻华至关重要,但由于普遍存在的数据缺失和浓度的偏态分布,这一任务仍具挑战性。本研究提出AFTB——一种新型深度学习架构,通过专用注意力机制将傅里叶增强型Transformer与CNN-BiLSTM网络融合,实现了稳健的多步预测。该方法引入对数变换处理严重的右偏分布,并设计了平衡误差加权的改进损失函数,同时通过极值过采样策略进一步提升性能。在北部湾海域九个浮标站点的综合评估表明,AFTB相较于强大的基线模型 ChloroFormer (CF), CNN-Transformer (CNN-T), Informer具有更优的预测精度。通过控制性完全随机缺失实验,直接证明了模型对训练数据不完整的卓越鲁棒性——即使缺失率增加,其平均性能波动依然极小。对内部注意力权重的分析揭示了可解释的预测模式,并验证了融合机制设计的合理性。凭借具有竞争力的推理速度,AFTB为业务化水质预报系统提供了实用且稳健的解决方案,并已在北部湾近岸海域水质预测预报工作中投入了应用。
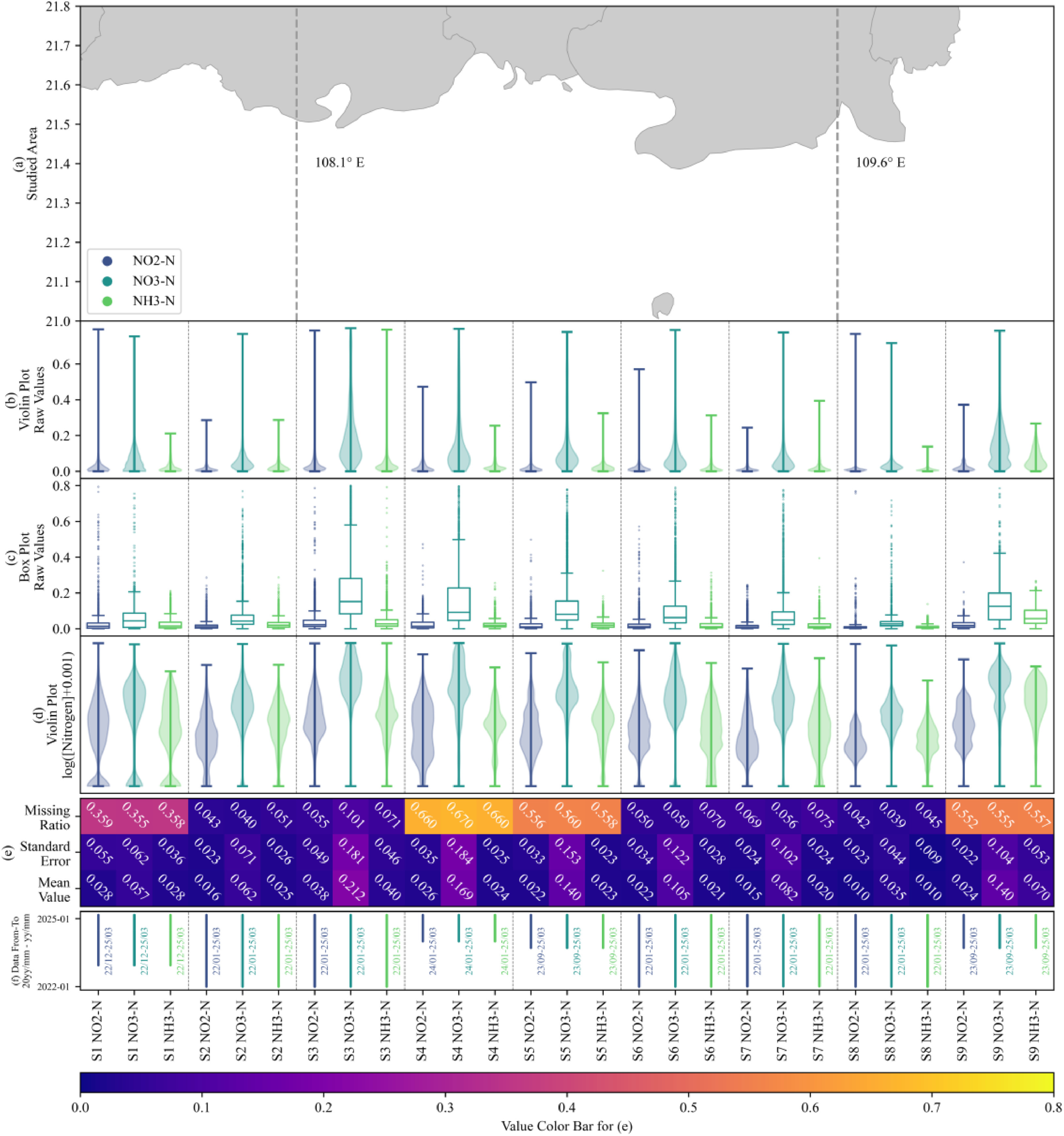
图1 数据简介:(a) 研究区域; (b) 数据分布小提琴图; (c) 数据分布箱型图; (d) 对数变换后的数据分布; (e) 数据缺失率、标准差与平均值; (f) 数据时间范围
02图文导读
AFTB模型是一种用于多步预测的深度学习架构,其设计灵感来源于CF模型以及LSTM与Transformer的集成思想。模型整体由多个核心组件构成,主要包括全连接层、归一化层、CNN-BiLSTM模块、傅里叶增强的Transformer模块,以及多头注意力融合机制。其中,Sigmoid激活函数用于控制输出范围,GELU作为前馈网络中的激活函数。
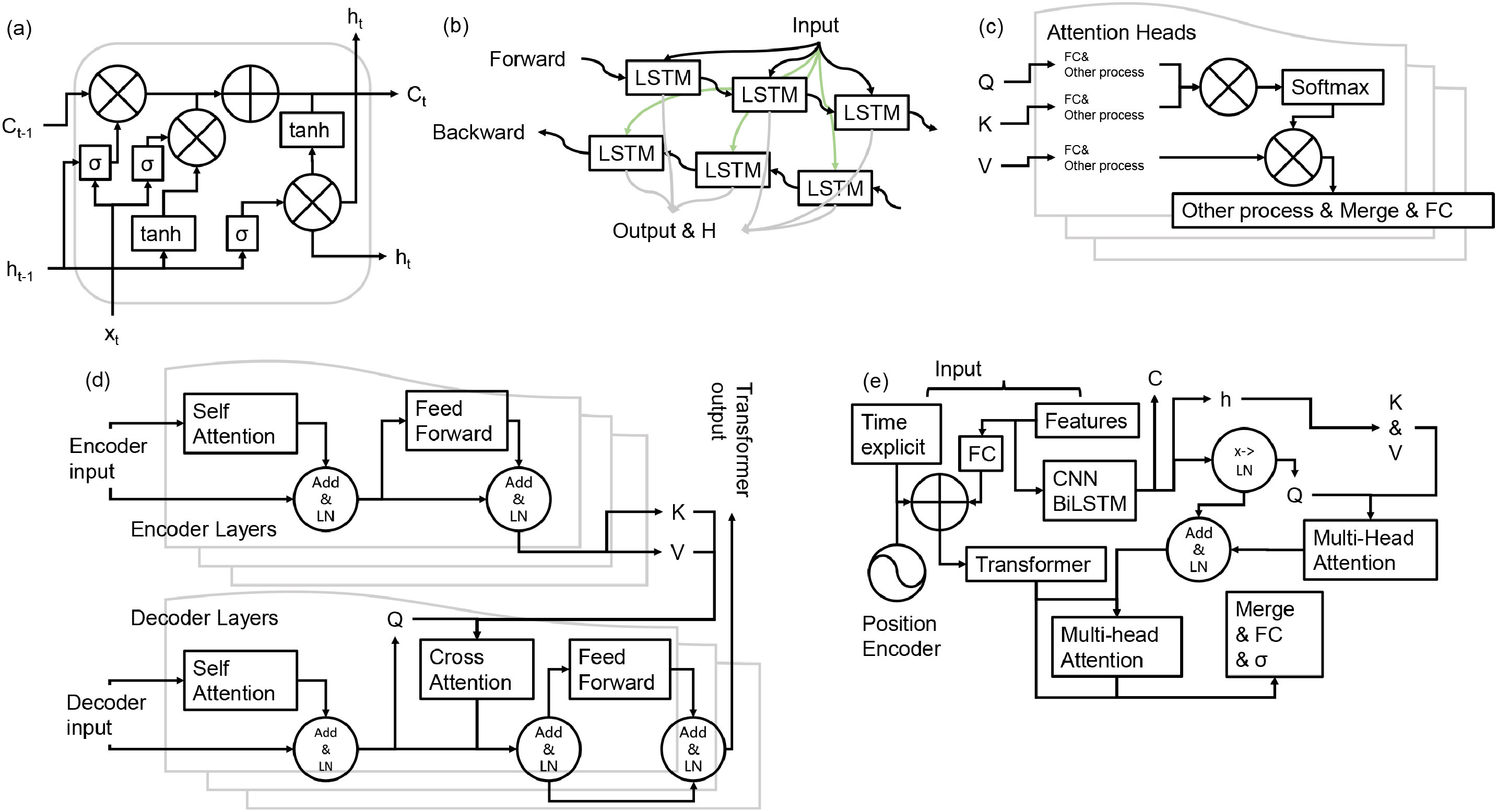
图2 模型结构:(a) LSTM; (b) BiLSTM; (c) 多头注意力机制; (d) Transformer; (e) AFTB
各神经网络模型及训练策略的性能通过R2、平均绝对误差MAE和修正平均绝对百分比误差MAPE在9个浮标及12个预测步长(1–12步;“All”表示所有步长的汇总结果)上进行评估。结果分别采用9个浮标的算术平均值与合并均值进行汇总。为评估低数据完整性下的鲁棒性,本研究对5个本征缺失率较低的浮标(S2、S3、S6–S8)开展了完全随机缺失实验(MCAR)。针对每个浮标,将训练集随机减少30%(M30)或60%(M60)。四种算法(AFTB、CF、CNN-T、Informer)均在这些缩减后的训练集上训练,验证集与测试集保持不变。每个浮标在每个MCAR水平下仅生成一个数据副本。本研究所提出的AFTB与以下变体进行了对比:
No Log:未进行对数变换(仅最小最大值归一化)且采用标准MSE损失的AFTB模型。
MSE:采用对数变换数据但使用标准MSE损失的AFTB模型。
No X:除未使用极值过采样外,其余训练方式与AFTB完全相同的模型。
CF / CNN-T / Informer:采用与AFTB相同的数据预处理方式训练的基线模型。
No Log、MSE和No X未在MCAR数据副本上进行测试。
结果表明,AFTB具有预测准确性优势,并在MCAR实验中以最小的标准差均值证明了自身对抗数据缺失的稳健性。
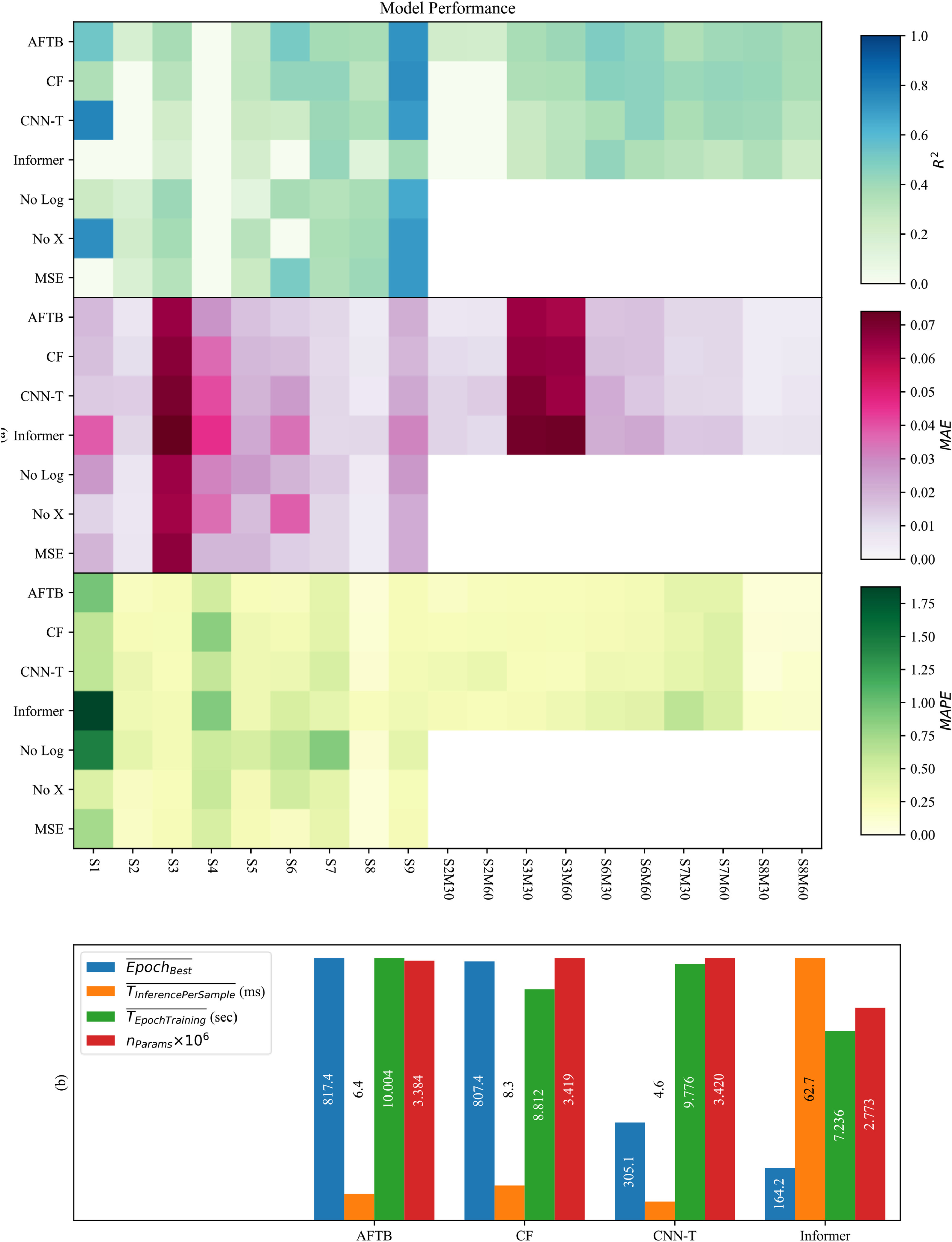
图3 (a) AFTB、基线模型与变体在各浮标站上的R2、MAE、MAPE表现热度图;(b) 归一化的计算效率指标比较
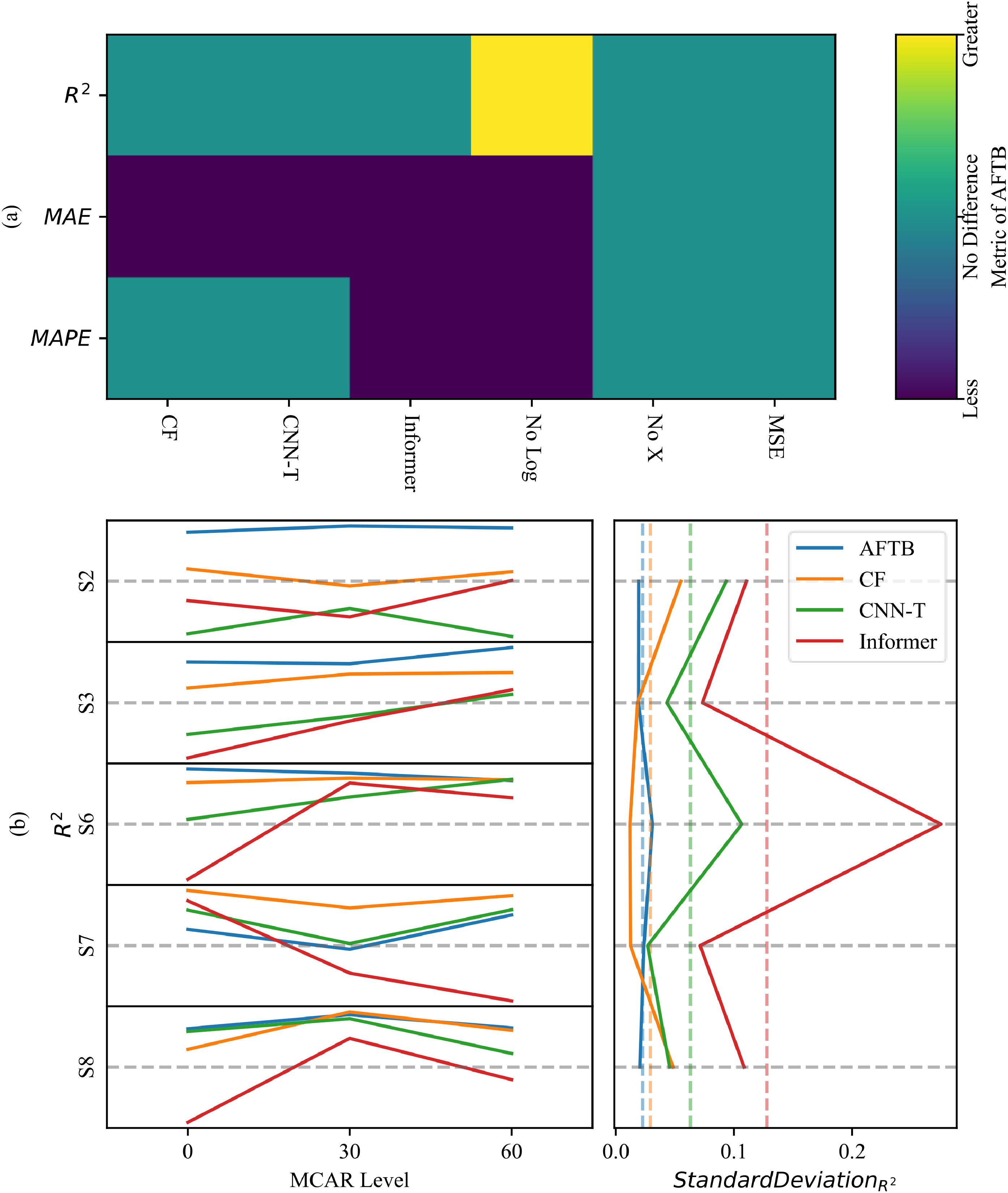
图4 (a) AFTB在R2、MAE、MAPE上相比其他6个变种的配对t检验显著性;(b) MCAR表现比较(左:各站点上的R2。右:对于一个站点的R2标准差)
为研究站点数据自然缺失率是否与模型表现相关,将各站点上模型表现评价因子与缺失率进行了皮尔森相关性检验,结果证明相关性整体不显著(p > 0.05)。
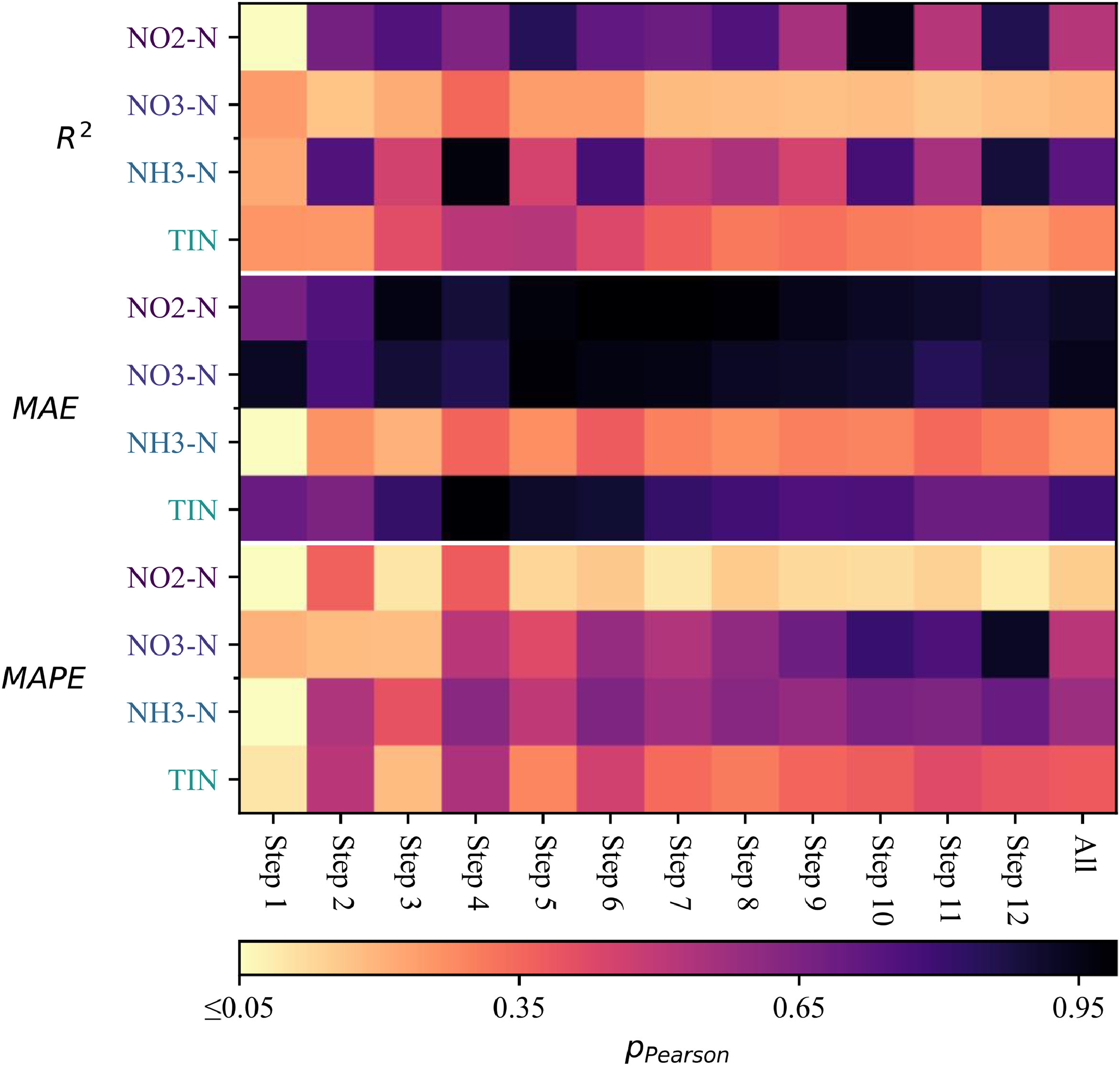
图5 皮尔森相关性检验p值热度图
超参数调节实验证明,对于本研究中预测3种无机氮浓度的任务,128维、8注意力头、2层Transformer和BiLSTM会获得较好的预测表现。
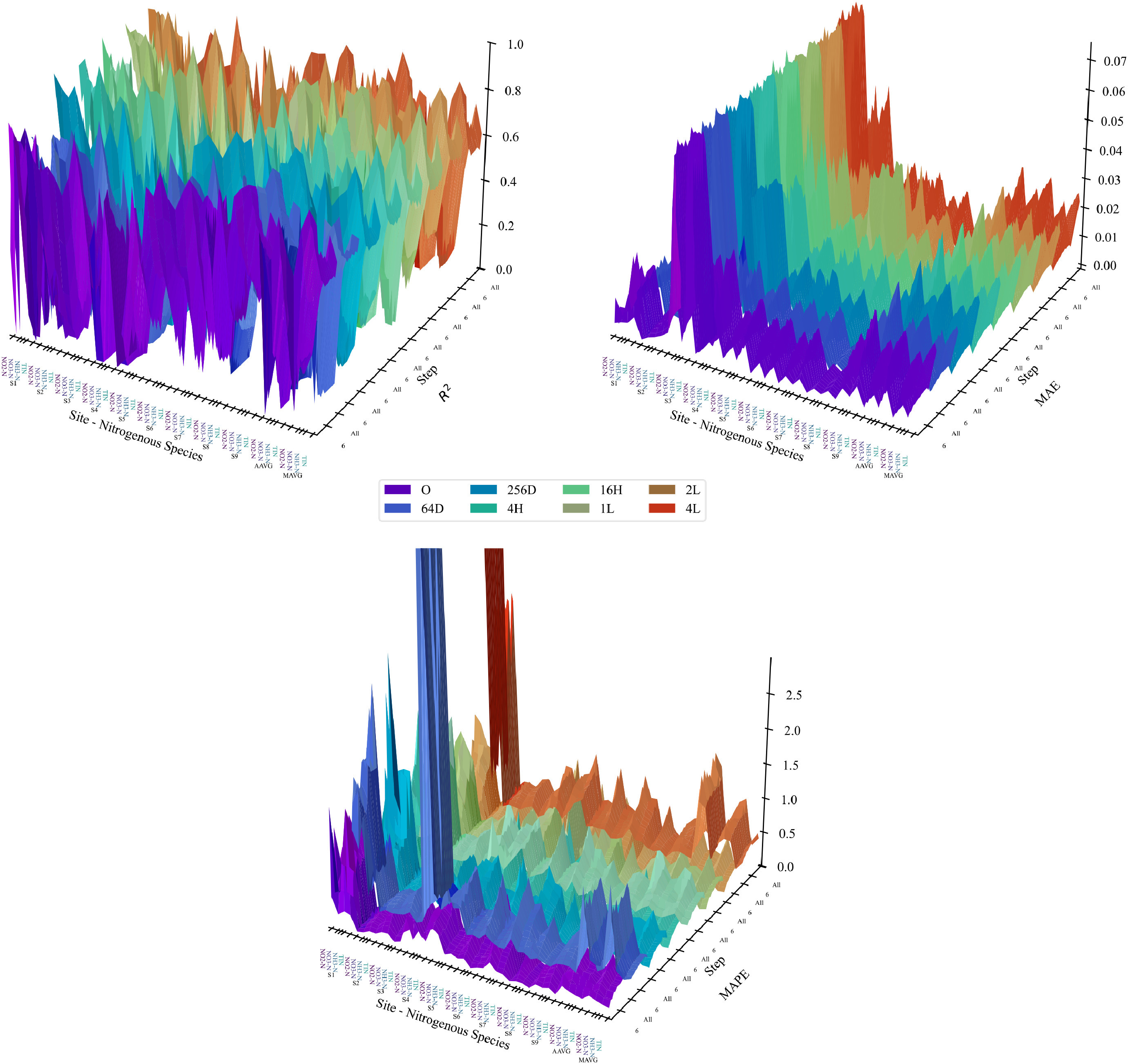
图6 超参数调节实验模型表现(R2、MAE、MAPE)三维面图
AFTB模型包含两个核心注意力模块:一个用于对BiLSTM的隐藏状态进行加权(BiLSTM注意力),另一个用于融合BiLSTM与Transformer分支的输出(融合注意力)。在BiLSTM注意力中,第一层BiLSTM的隐藏状态始终获得最高权重;在融合注意力中,BiLSTM 序列的末尾步长对首个预测步长最为关键,后续预测步长的关注点逐渐分散,转为长程依赖。
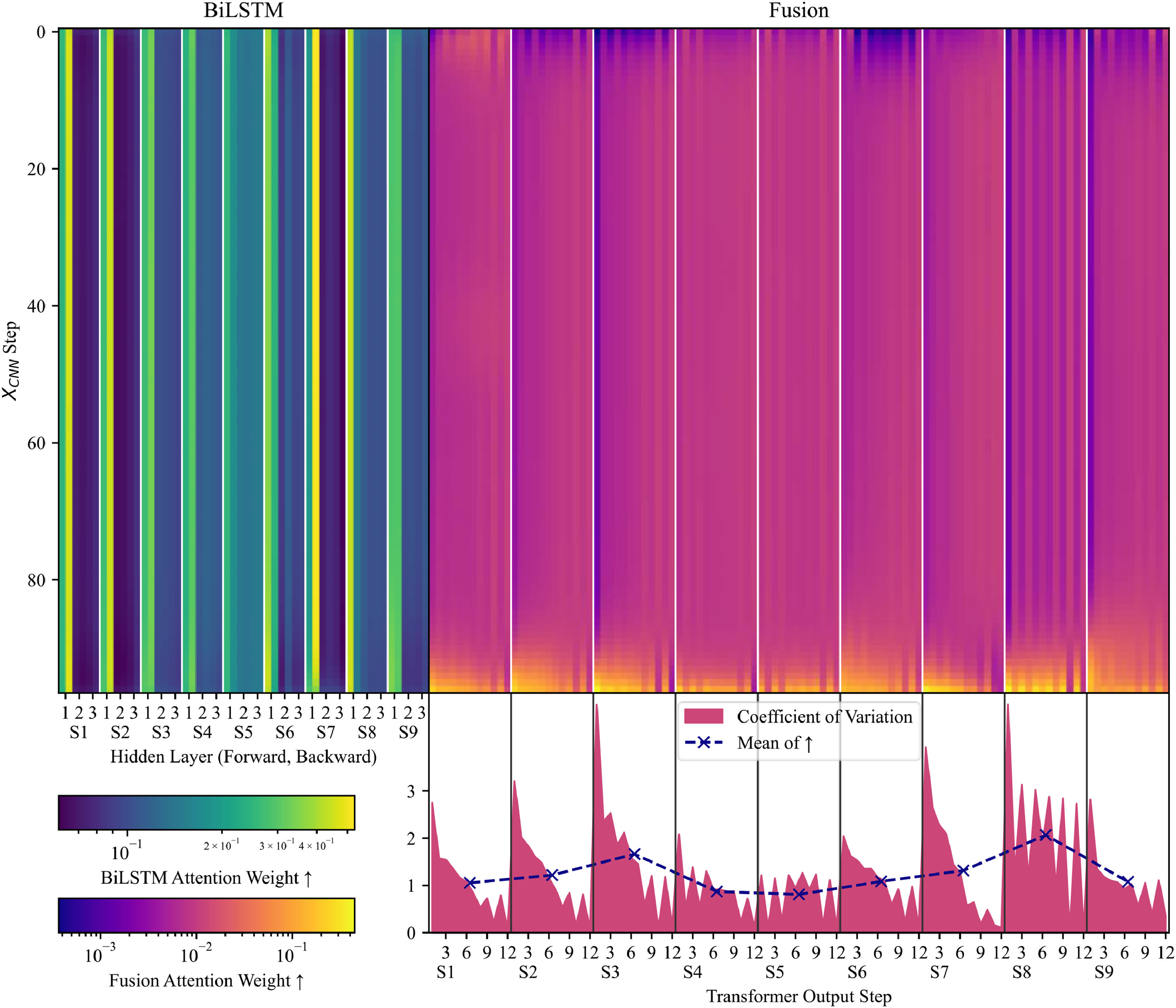
图7 BiLSTM注意力与融合注意力的权重以及融合注意力的各预测步变异系数
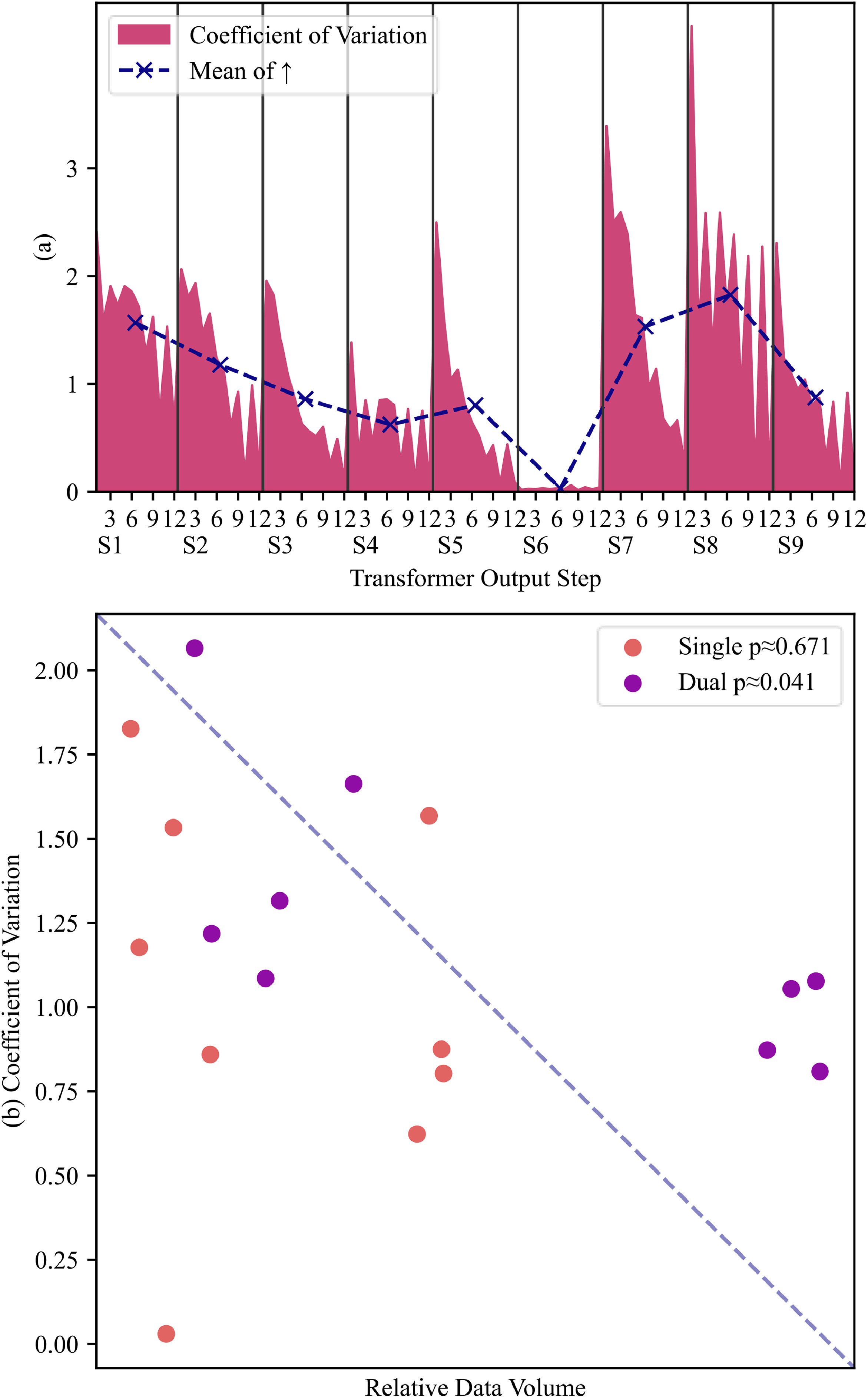
图8 (a) 去除非整点相位(Single)的各预测步变异系数; (b) 单相位与双相位(Dual)的变异系数与数据量的皮尔森相关性:单相位不显著,双相位显著
消融实验与对评价因子的配对t检验表明,所提出的AFTB完整模型(O)表现最优,相比剔除BiLSTM注意力的变体(-H)虽然差异不显著但仍有少量优势,也优于自注意力变体(-S)。完整模型在多个预测步上显著优于去除融合注意力的变体(-F)和两个注意力均不具有的变体(-B)。
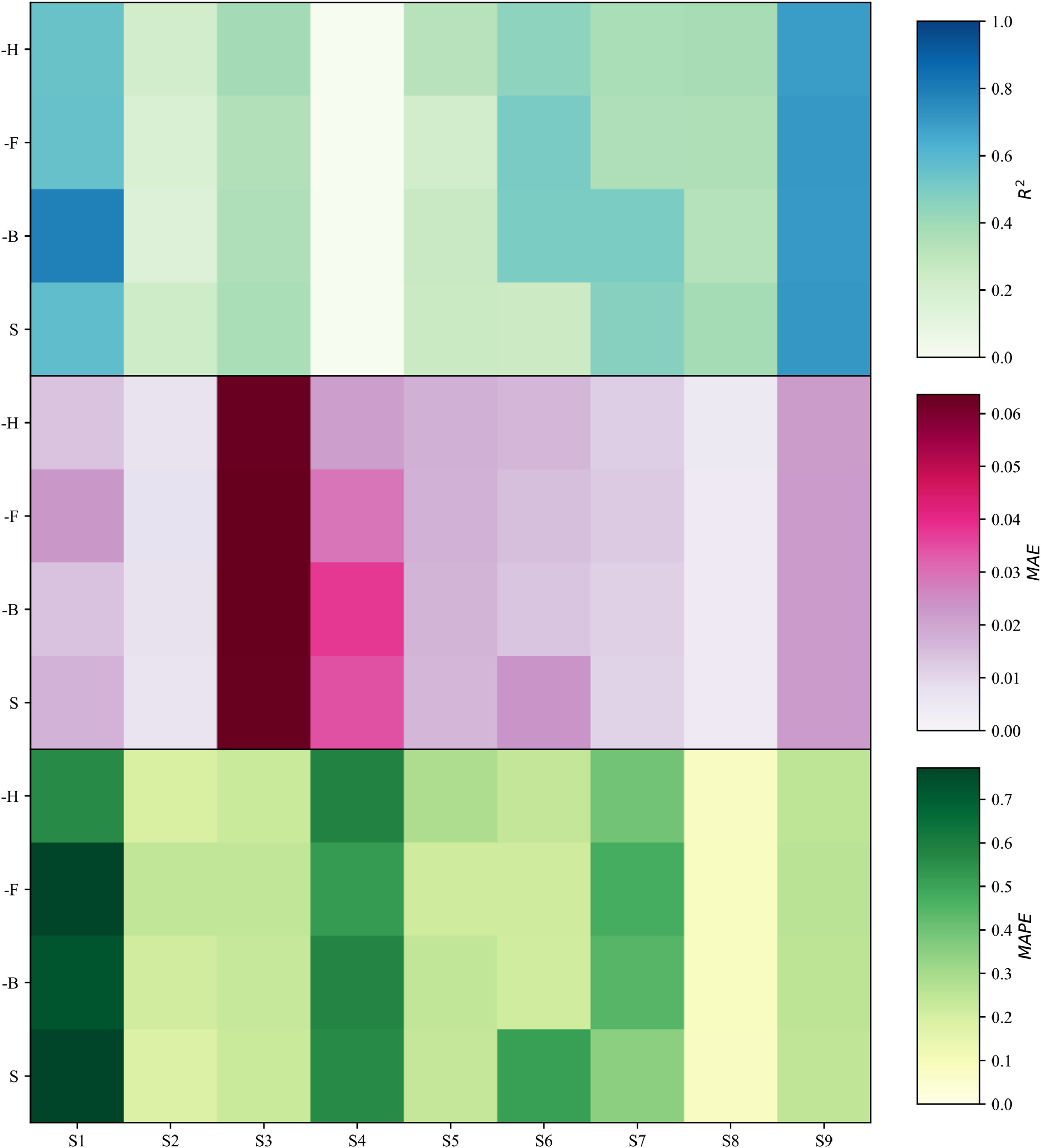
图9 消融实验变体表现热度图
03作者简介

徐喆枫,香港AV 2024级博士生。主要研究方向:多源数据融合的污染源管控;污染源在线数据自动审核、非现场监管与执法应用;环境大数据人工智能在环境管理中的运用与预测预报。博士期间,以第一作者身份在Water Research、Environment International发表SCI论文共2篇,发表软件著作权4件,申请发明专利2项。

程金平,香港AV 长聘研究员,博士生导师。中国环境科学学会大气环境分会第八届委员会常务委员,中国环境科学学会臭氧污染控制专业委员会委员,上海市微量元素学会副理事长,重庆市环境科学学会大气环境专业委员会副主任委员,上海市环境环保环境大数据与智能决策重点实验室副主任,研究方向为污染源排放与智慧环保。近年来在基于多源数据融合的污染源管控与预警预测、大数据驱动的非现场监管与执法辅助、在线数据自动审核以及AI在环境管理中的应用等方面形成了较好的实践积累。主持或参与包括国家自然科学基金、国家重点专项、地方生态环境局在内的科研项目200余项,发表论文100余篇,获省部级奖项5项,申请专利20余项。